



Data Science I & II
Course Description
Part I runs in the winter semester and pursues three main goals. First, we build up the R skills required to investigate all subsequent topics in R in a hands-on fashion. No previous programming experience is required. Second, we cover the first steps of the data processing pipeline in data collection, preparation and visualization – honing our R skills along the way. Third and finally, we turn our attention to modelling with a focus on supervised learning. This part includes basic regression and classification models, feature engineering and model evaluation.
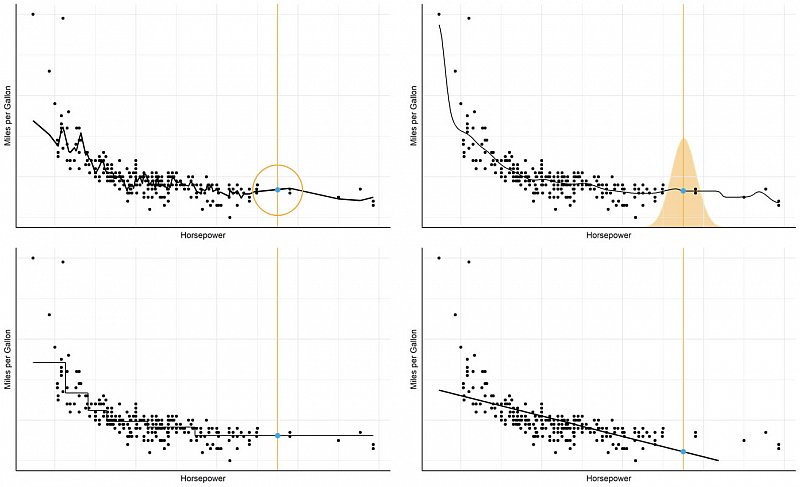
Part II in the summer semester builds on part I. First, we enhance our model toolkit with more advanced models and feature engineering methods. Second, we take a step back and investigate the notion of generalization, i.e. under which circumstances we can hope to learn anything at all about the world from our data. We will discover strategies to achieve generalization and learn to select models based on these strategies.
Course Structure
The hands-on nature of these modules requires us to build hard skills in part I of the sequence. The winter semester thus consists of three weekly sessions: a lecture, the discussion of a complementary R Script, and an exercise where we discuss the solutions to the weekly R assignments. You may opt to work through the R script yourself and then complete the assignment but especially beginners greatly benefit from the extra session in R that puts them on track to do the assignments.
Participants of part II in the summer semester are expected to bring sound command of R (or the willingness and effort to catch up). There is a weekly lecture and a complementary R session in which we revisit the content.
Content
This is a rough sketch of the course content. Especially the content of part II is still tentative. Current topics at the end of the course are subject to change and updated regularly.
| Week 1 | Introduction |
| Week 2 | Data |
| Week 3 | Data Collection |
| Week 4 | Data Preparation |
| Week 5 | Visualization |
| Week 6 | Introduction to Modelling |
| Week 7 | Linear Regression |
| Week 8 | k-NN, Tree Regression, Smoothing |
| Week 9 | Logistic Regression |
| Week 10 | MNL Regression, Decision Trees |
| Week 11 | Model Evaluation |
| Week 12 | Features I: Engineering |
| Week 13 | Guest lecture: Applications in Business/Economics |
| Week 14 | Features II: Clustering |
| Week 15 | Summary, Outlook, Exam preparation |
| Week 1 | Recap, Empirical Loss Minimization |
| Week 2 | Features III: PCA |
| Week 3 | Features IV: Kernels & Adaptive Basis Functions |
| Week 4 | TBD (SVM) |
| Week 5 | Neural Networks I |
| Week 6 | Neural Networks II |
| Week 7 | Generalization |
| Week 8 | Validation, Information Criteria |
| Week 9 | Regularization, Model Selection |
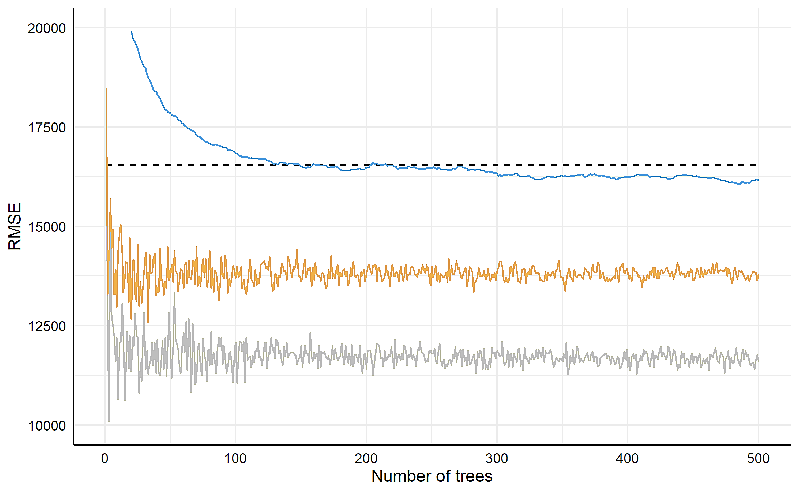
| Week 10 | Ensembles: Bagging |
| Week 11 | Ensembles: Boosting |
| Week 12 | Probabilistic Models I: Maximum Likelihood |
| Week 13 | Probabilistic Models II: Mixture Models |
| Week 14 | Guest Lecture |
| Week 15 | Current Topics |
Coursework
Part I
For part I, you will conduct your first small data analysis of a dataset of your choice. You will pick a regression or classification question, explore a suitable dataset, engage in feature engineering, run and evaluate at least 2 different models and hand in your work as a reproducible R notebook. In an oral exam, we will discuss your notebook and other topics covered in the course.
Data Science I - Coursework
Coursework_DataScience_I.pdf
(113,2 KB) vom 09.03.2023
Examples
To meet popular demand, here are some (slightly modified) examples of previous submissions. They highlight different aspects of the coursework. These examples are not free of errors and not meant to be copy/paste templates. But they are excellent examples of students demonstrating their ability to independently inquire into their chosen datasets using R; employing, adapting and extending the R code from the course scripts; and putting in considerable effort. Good scripts are also characterized by a description of the thought process as the inquiry unfolds. They do not hide/remove parts of the script that did not improve the model but state the conclusions drawn from such parts instead. This coursework is not a Kaggle competition and predictive performance is not graded.
Example - Data Collection
StudentExample_Data_Collection.html
(676,7 KB) vom 09.03.2023
Example - Data Preparation
StudentExample_Data_Preparation.html
(1,7 MB) vom 23.03.2023
StudentExample_Data_Description_ Model_Evaluation
StudentExample_DataDescription_ModelEvaluation.html
(1 MB) vom 23.03.2023
Part II
For part II, you will once again pick a regression or a classification problem, run both basic and advanced models, evaluate and compare their performance, engage in model selection based on model generalization and hand in your work as a reproducible R notebook. Your work will be presented and discussed in class.
Examples
Examples will follow later as the format of the coursework has changed.